A high-quality model requires consistent annotations. That's why the Hyperscience application has a tool, called Labeling Anomaly Detection, for identifying potential discrepancies in the training datasets before running model training. Once the annotations are ready, the user can analyze the data to find inconsistencies and ensure a top-performance locator model.
In v37+, this tool is available for both Field Identification and Table Identification models. Learn more about Field anomaly detection in Detecting and Correcting Anomalies in Field Annotations.
Limitations of Table ID Labeling Anomaly Detection in v37 and above
Table Anomaly Detection won’t capture all errors in the annotations
If a column is missing, the other documents in the same group must have that column to detect it as an anomaly.
You can run Labeling anomaly Detection for up to 5,000 pages at a time
Detecting anomalies
Labeling Anomaly Detection now includes anomalies generated from Model Validation Tasks after training in previous versions. For more information, see Model Validation Tasks.
Before using Labeling Anomaly Detection, make sure that you've uploaded the required number of training documents.
Go to Library > Models, and make sure Identification Models are selected from the drop-down list at the top of the page.
Find the model you want to work on, and click on its name to access its Model Details page.
On the Model Details page, click on the Table Identification tab.
In the Training Data Health card, click Analyze Data.
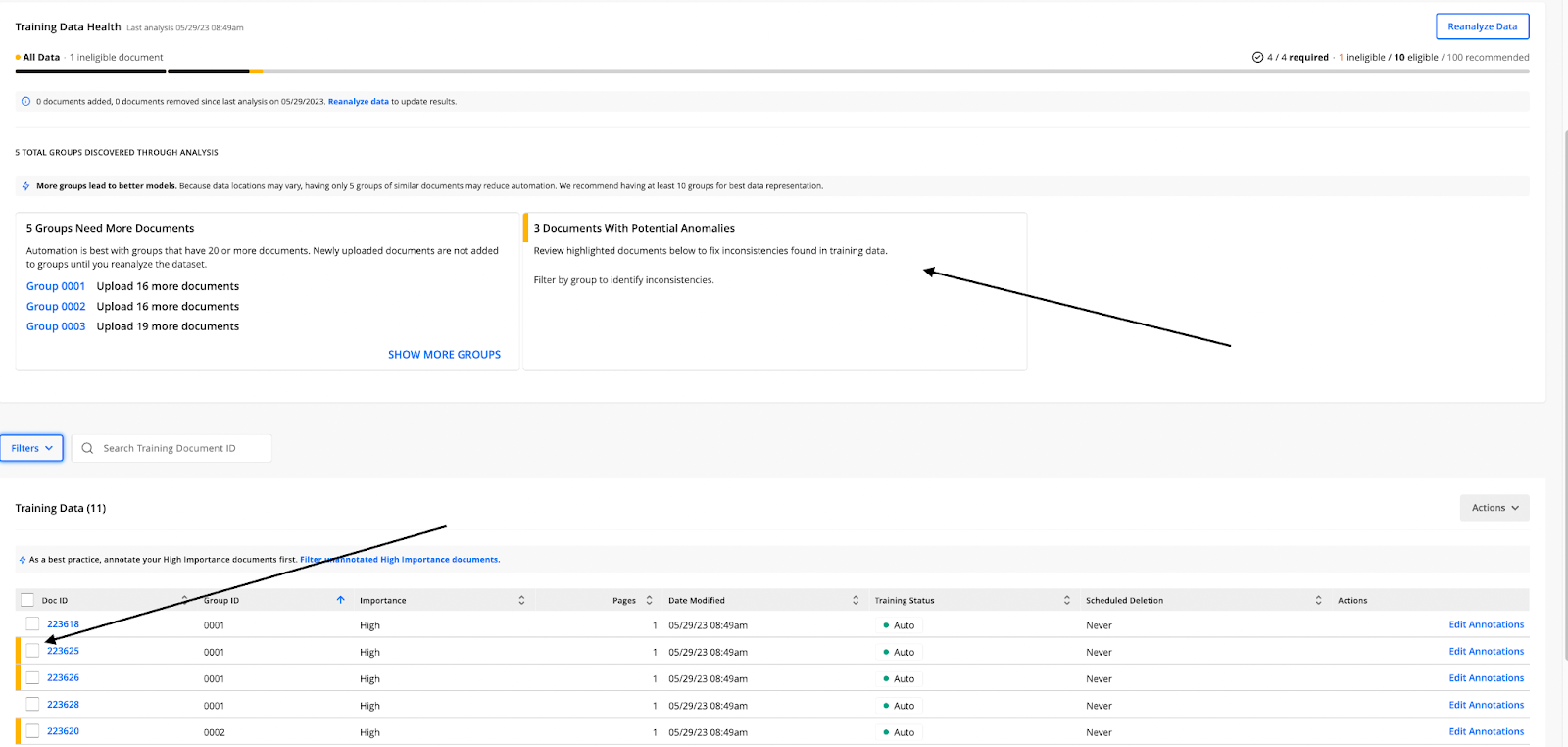
The analysis shows the training data’s health: the number of required documents for training, along with the training-eligibility status, importance, and group assigned to each document.
Learn more about grouping in Training Data Analysis and Guided Data Labeling and about training eligibility in Document Eligibility Filtering.
Re-analyze your data after annotating the documents with High importance.
If anomalies were detected during the analysis:
A count of documents with potential anomalies appears on the Training Data Health card.
Each document containing potential anomalies is highlighted with a yellow bar on the left-hand side of its entry in the Training Data table.
Reviewing Anomalies
Above the Training Data table, click Filters, and then select a group from the Group drop-down list.
Click Apply Filters.
Click the Edit Annotations link for a document highlighted as having potential anomalies.
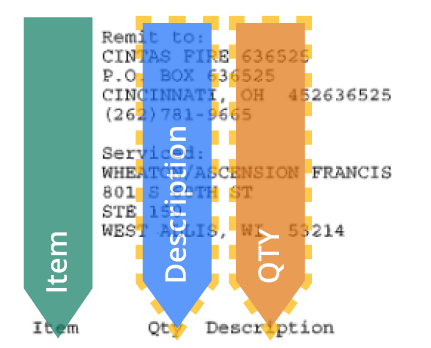
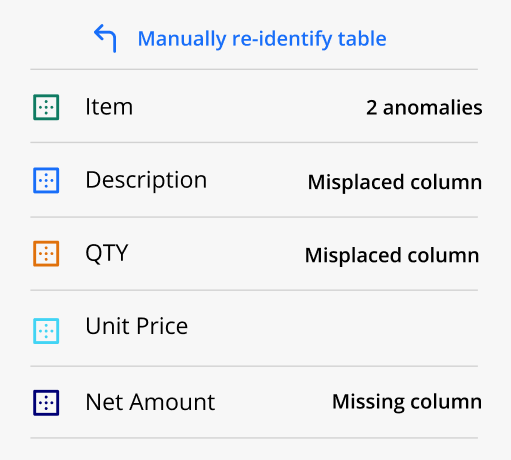
The right-hand sidebar shows the potential anomalies.Click on a column to access its action buttons.
You can select columns by clicking on the colored labels or the column names on the right-hand sidebar. You can also use the W and E keys on your keyboard.
Do one of the following:
Make the required correction (adjusting the bounding box, annotating the missing cell, etc.) When you do so, the anomaly disappears.
Annotate any missing columns to remove the “Missing column” label.
If the column is not present in the document, click on the checkmark in the column’s colored marker to remove the label.
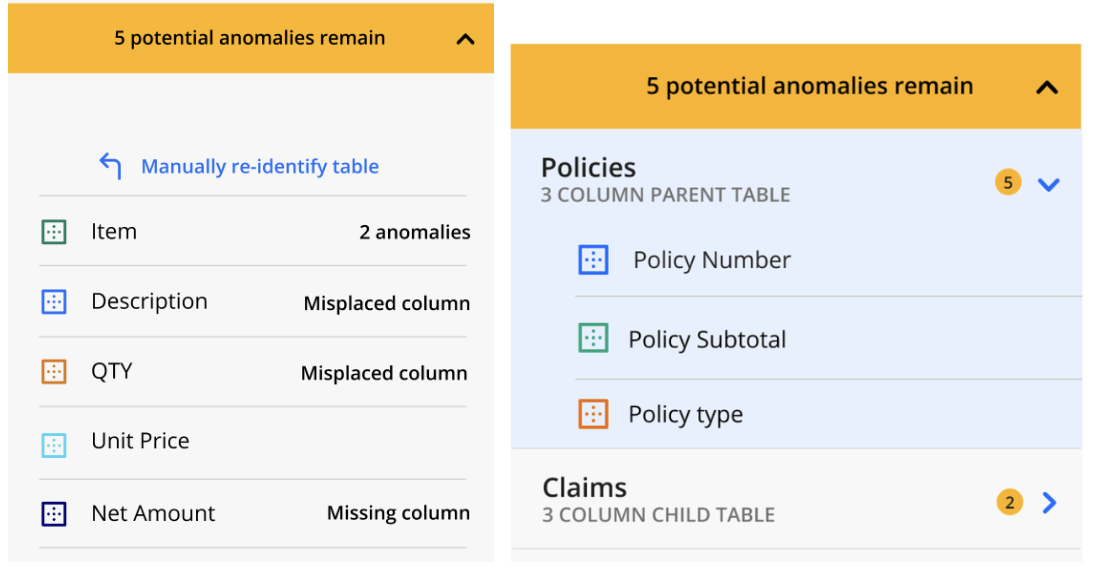
If a nested table contains anomalies, click on the name of the parent or child table in the right-hand sidebar. Then complete steps 4-5.
Learn more about nested tables in Table Identification.
If the anomaly appears correct, click on the checkmark in the column’s colored marker to remove it.
Always make sure to reanalyze your data for updated information on the training set. If documents have been added, removed, or modified since the last analysis, the ineligibility details may be outdated.
Anomaly indicators
The indicators described in the table below appear in the document viewer if anomalies are detected in the document.
Indicator | Description | Example |
|---|---|---|
Cell-anomaly indicator - found in the right-hand sidebar | Dotted line around a cell - indicates a cell that needs to be reviewed Gradient indicator - shows places where the model suggests a cell should be | |
Page Indicator - found in the left-side sidebar | Dotted line around a page - indicates cell-level anomalies on the specific page | |
Missing columns label - found on the top of the document, next to the colored markers for each column | The indicator for a missing column is a dotted, transparent label, located next to the bookmark indicators for each column. It indicates all possible missing columns on a document level. | |
Missing column tag - found in the right-hand sidebar next to the specific column that is missing | This tag shows the specific missing column. | |
Misplaced column - found around the colored markers for columns | Dotted line around the colored markers - indicates misplaced columns | |
Misplaced column tag - found in the right-hand sidebar next to the specific column that is misplaced | This tag shows the specific misplaced column. | |
Number of anomalies - found in the right-hand sidebar above the list of columns in the document | This yellow indicator displays the current number of potential anomalies in the document. It is dynamic and changes after each interaction with an annotation labeled as an anomaly. If you have a nested table, the number of potential anomalies will also appear next to the name of the parent or child table. | |
Checkmark - action button, located in the colored label for a column | The checkmark appears for single and multiple anomalies in a column. Click on it to mark a column/cell as correct. Single anomaly - hover over it to see the specific anomaly Multiple anomalies - hover over to see the number of potential anomalies for this column |