Accessing this feature
Your access to the feature described in this article depends on your license package and pricing plan.
To learn which features are available to your organization and how to add more, contact your Hyperscience representative.
In this article, you’ll learn how to navigate through and use Training Data Management for Identification models. Learn more about each feature in Training Data Management.
Accessing TDM for Identification models
Each identification model trained for the specific Semi-structured layout has its tab on the Model Management page (i.e., Field Identification or Table Identification). Find the type of model you want to manage by clicking on its respective tab.
You can upload or download training documents by clicking the buttons in the page's upper-right corner.
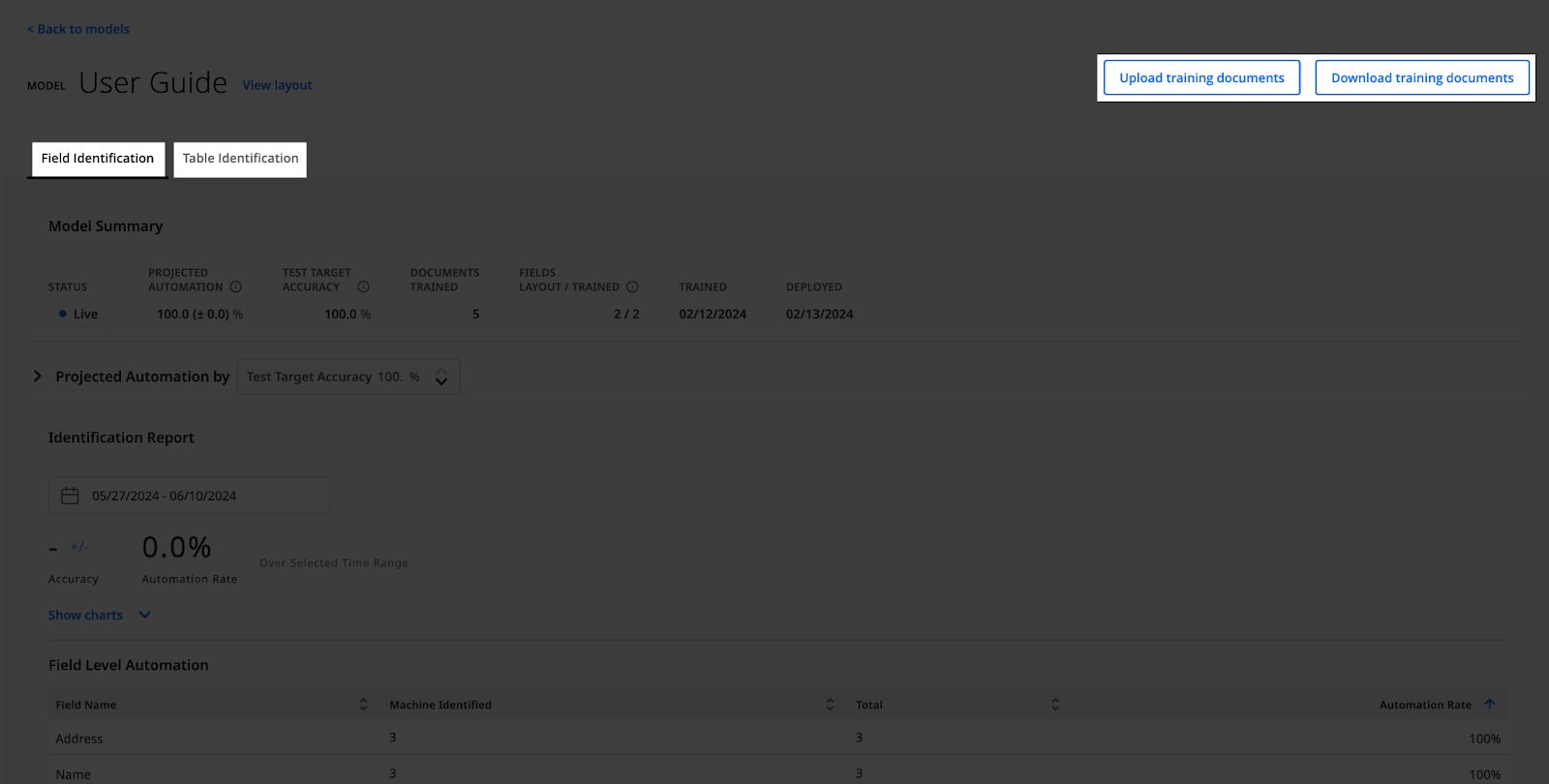
Navigating TDM for Identification models
Model Summary card
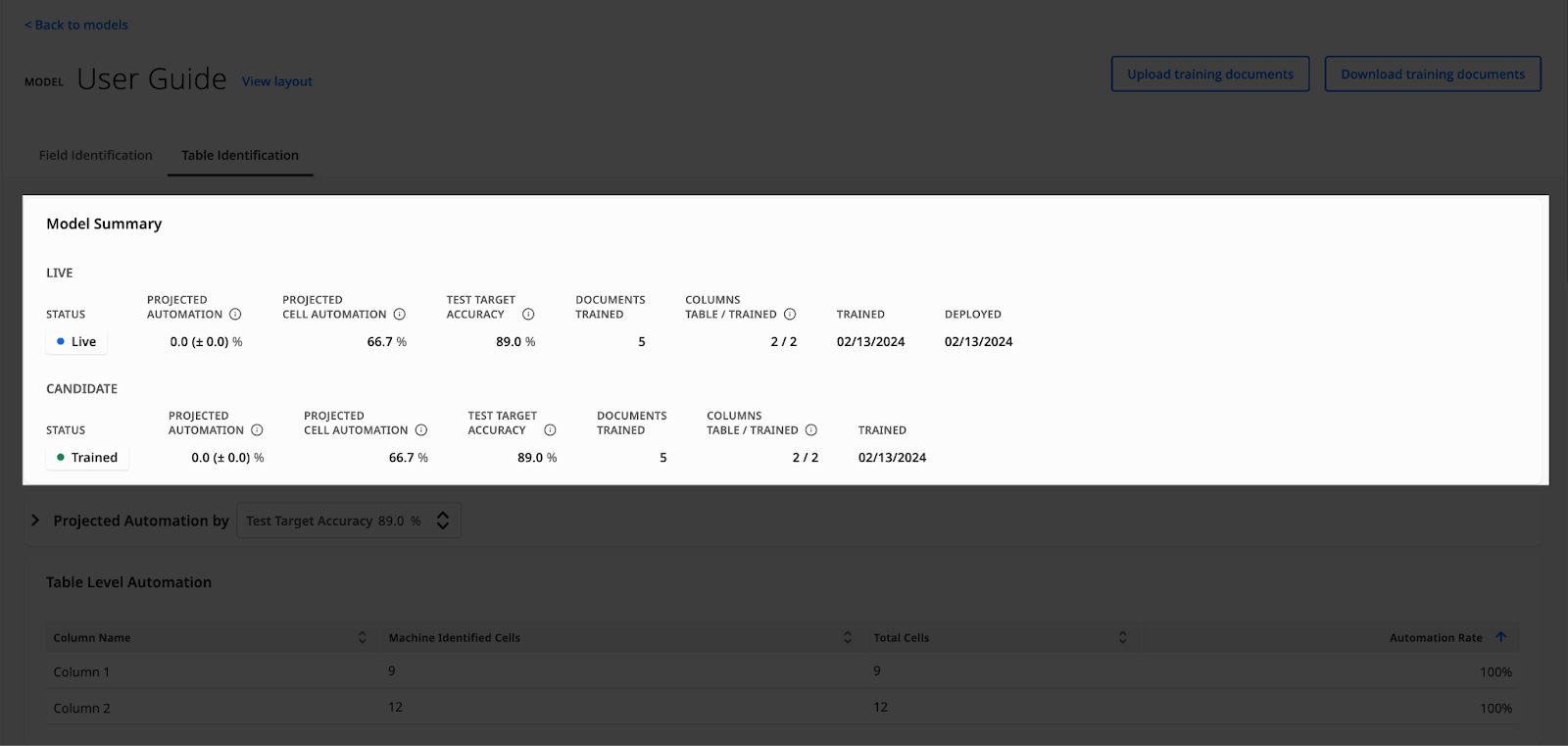
The Model summary card displays this layout's Live and Candidate models. You can see the following information:
Status — the current status of the model:
Live — The model is deployed.
Trained — You have a candidate model ready to be deployed.
Uploaded — The model was uploaded.
Failed — The model training has failed.
Training — The model training is still in progress.
Requirements not met — The requirements for training a model are not met. Learn more in Requirements for Training a New Model.
Analysis running — Training Data Analysis is in progress.
Queued — The model is scheduled for training in the queue.
Projected Automation — displays the predicted automation, based on the Test Target Accuracy. Learn more in our Evaluating Model Training Results article.
Projected Cell Automation — displays the projected automation per cell, based on the Test Target Accuracy.
Test Target Accuracy — the accuracy percentage used to calculate the projected automation. You can adjust it from the Model History card.
Documents Trained — the number of documents used for training the model.
Fields Layout / Trained or Columns Table / Trained — The number of fields or columns in the current live version of your layout, and the number of fields or columns used for training the model.
For example, if you train a model with 5 fields or columns but remove a field or a column from the current layout version, the numbers will be 4 / 5 (i.e., the layout has 4 fields or columns, but the model was trained on 5).
Trained — date the model was trained.
Deployed — date the model was deployed.
If the requirements for training a model are not met, then the model summary card will display the status “Reqs not met,” and a View training data button will appear on the card. It will redirect you to the Training Data table.

If your model is ready for training, the status “Ready to train” will appear on the model summary card. You’ll be able to start training by clicking the Train button located on the right-hand side of the card.

If you want to cancel your training, you can click the Cancel training job button next to the status of your model in the model summary card.

Projected Automation chart
The Projected Automation chart displays the performance of the model that’s currently live.
Expand it by clicking the arrow (
).
The chart displays how the target accuracy affects the automation. The lower the accuracy, the higher the automation, and vice-versa.
Note that projected model performance (i.e., accuracy and automation) can increase by adding more QA documents. You can also see the margin of error (MoE) for this model.
The Margin of Error (MoE) indicates the allowable range of inaccuracy in the system's results. It shows you how much the output can differ from the true value while still being acceptable. A smaller margin of error means the system is more accurate.
Adjust the Target Accuracy percentage by clicking the up and down arrows.
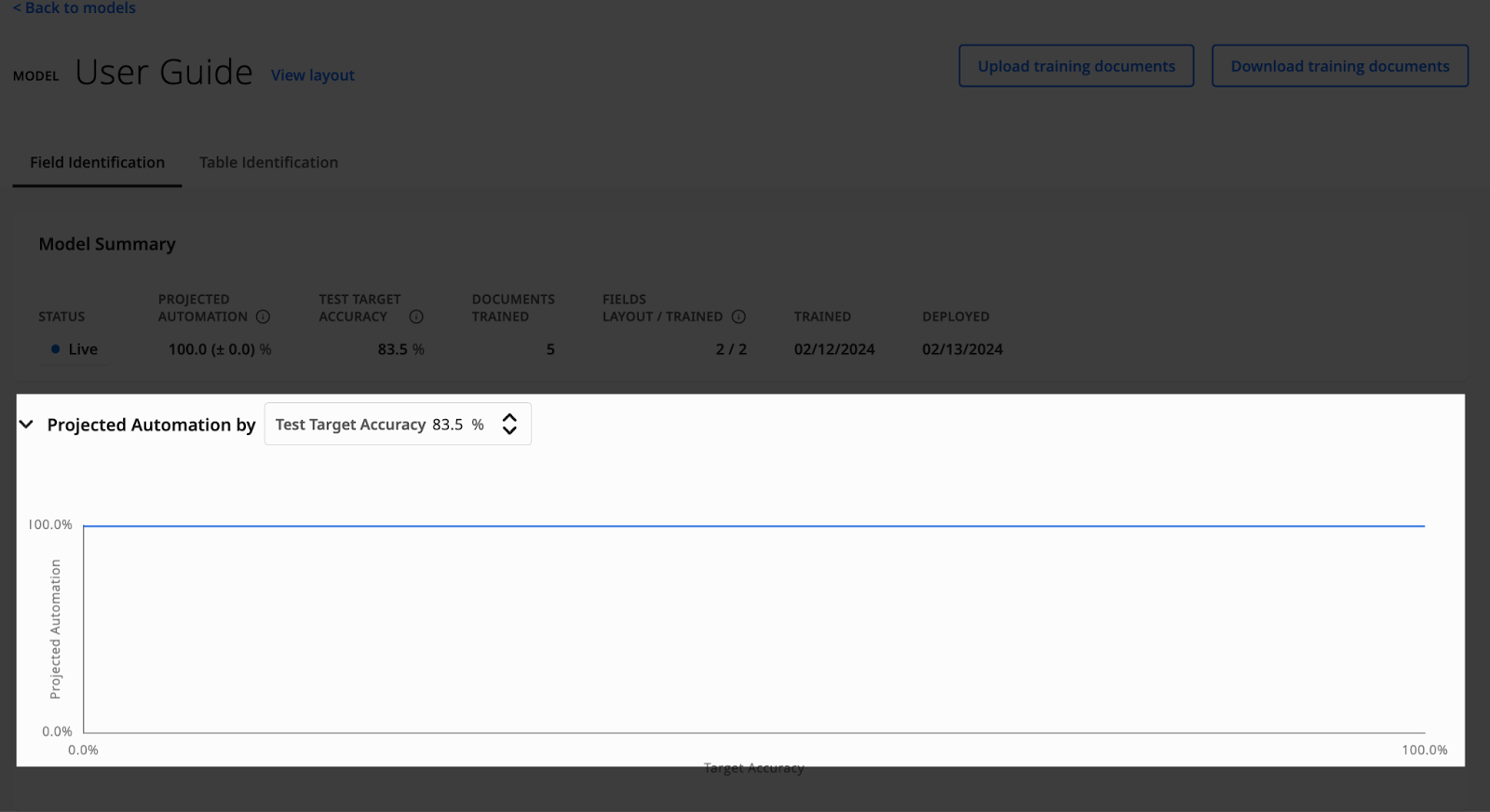
The chart will display the projected automation of your model with the target accuracy you specify. You can determine the target accuracy value that best meets your needs by entering test values.
Identification Report
The Identification Report displays the number of identified fields (whether the machine or a human identified them), their accuracy, and the field-level automation (i.e., the automation of the fields the model was trained on).
The Identification Report is available only for Field Identification models.
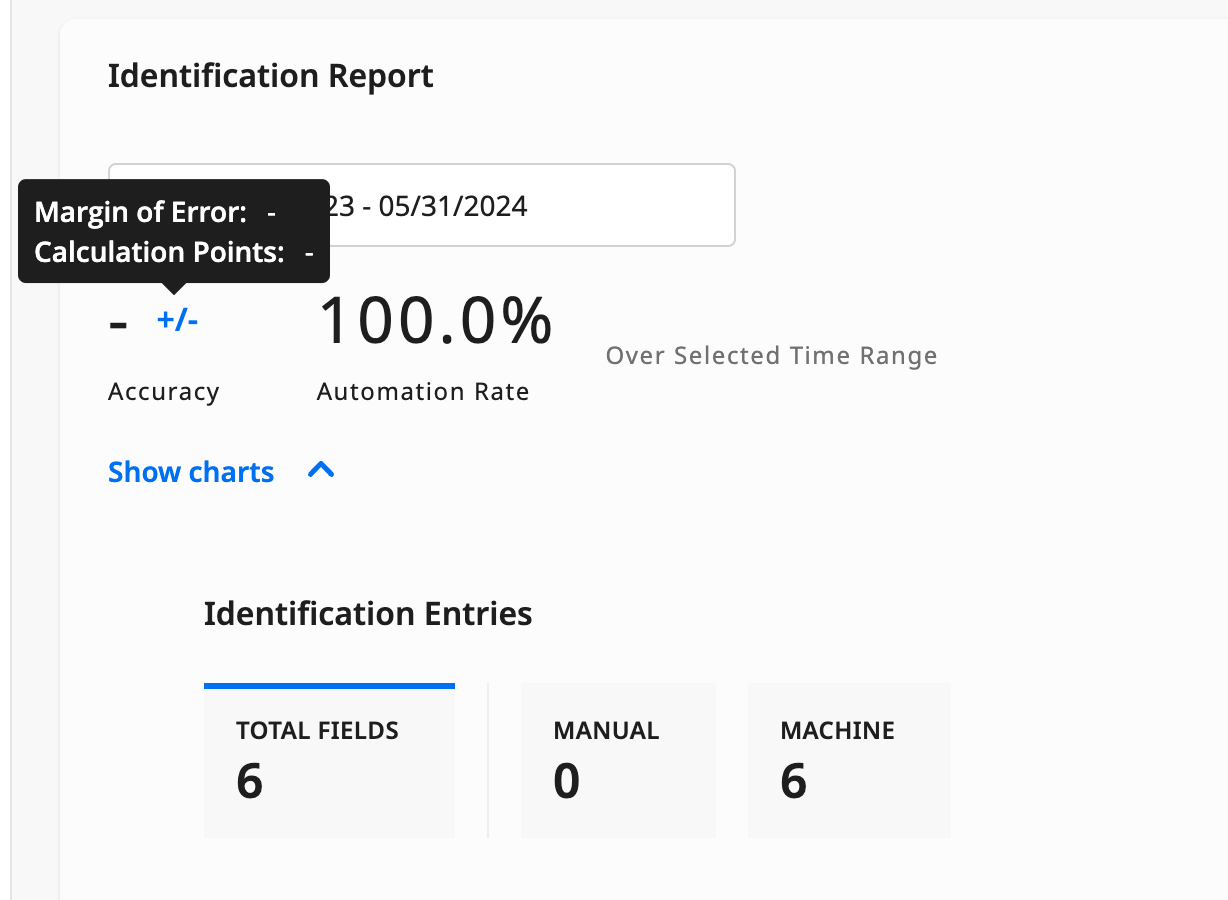
Select a specific date range for the report to see charts for the total number of identified fields (machine-identified and human-identified) and their respective accuracy values.
You can also see the Margin of Error, the calculation points, and the automation rate for the selected period. Hover over the Accuracy value to see the MoE and the Calculation points.
Hover over the Accuracy value to see the MoE and the Calculation points.
Calculation points are the total fields used to calculate accuracy. They represent the number of evaluated fields. For instance, an accuracy of 50% could come from 1/2 or 400/800 evaluated fields. Learn more in our Accuracy article.
Fields Identified Chart
The Fields Identified chart displays the number of machine- and manually-identified entries for a specific period.
You can filter the Identification Entries by clicking the Total Fields, Manual, and Machine buttons located at the top of the chart, or Machine Field ID or Manual Field ID located below the chart.
Hover over the chart’s data to see the specific date and the number of fields identified by the machine or by a human.
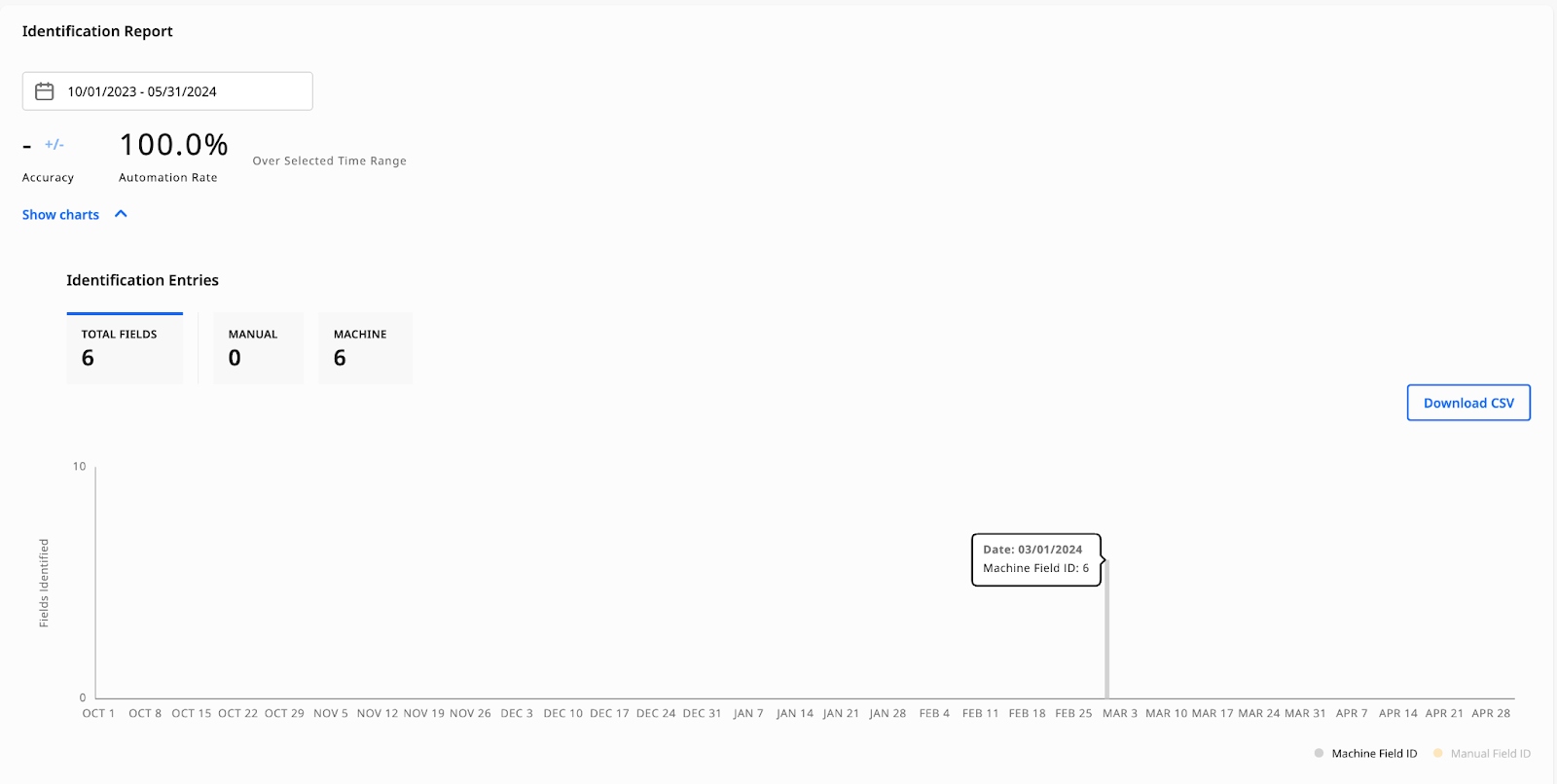
Download the data as a CSV file by clicking the Download CSV button located on the right-hand side of each chart.
Field Identification Accuracy Chart
The Field Identification Accuracy chart displays the percent accuracy for the selected time. You can see:
Field Identification Accuracy
Manual Accuracy
Target Accuracy
Field / Table Level Automation
The Field / Table Level Automation card displays the automation percentage of the fields or columns your model was trained on:
Field Name — displays the name of the field in your layout
Machine Identified or Machine Identified Cells - indicates the number of values identified by the machine for that field or for that column
Total or Total Cells — the total number of values identified for this field or column
Automation Rate — the percentage of automation for the specific field
You can sort each column and select the number of rows to display on the page.
.png?sv=2022-11-02&spr=https&st=2025-06-27T20%3A17%3A15Z&se=2025-06-27T20%3A36%3A15Z&sr=c&sp=r&sig=ceGg9I%2FT2HlNmmhml8NCzkOJd24WZUkBVkd6qtEhwM0%3D "image(40).png")
Training Data Health Card
The Training Data Health card displays a breakdown of your dataset. It shows the following insights on the uploaded documents:
The number of additional documents recommended for training. These documents do not include the minimum required for training to begin. Our recommendation is 100 documents.
Required — the number of documents required for training a model. The default number is 100. If you would like to change it, contact your Hyperscience representative.
Number of ineligible/eligible documents:
Ineligible documents — documents that do not meet the criteria for processing
Eligible documents — documents that meet the required criteria and can be used for model training
Learn more about eligibility in Document Eligibility Filtering.
Number of added or removed documents since the last training data analysis
Number of groups discovered during the training data analysis
Number of documents with potential anomalies
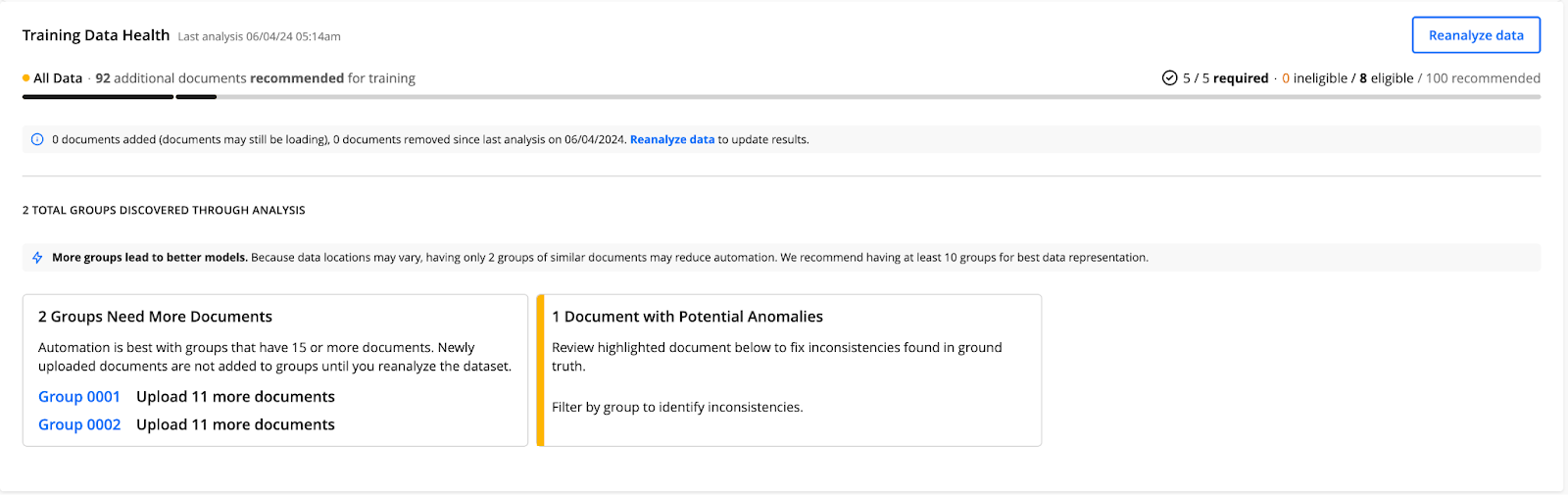
Analyze your data by clicking the Reanalyze data button.
Learn how to optimize your data and achieve better model performance by using Training Data Analysis, as described in Step 4 of Training a Semi-structured Model.
Training Data Table
The Training Data table shows all documents available for use as training data for your model. You can filter the contents of the table by training document ID, group ID, number of pages, submission date, training status, and scheduled deletion. You can also search for documents by their IDs.

Selecting at least one training document allows you to use the Actions drop-down menu. This drop-down menu has the following buttons:
Remove training documents – remove the selected training documents and their associated annotations
Edit training status – change the training status of the selected training documents that have been annotated. All unannotated training documents that you’ve selected will keep their current status.
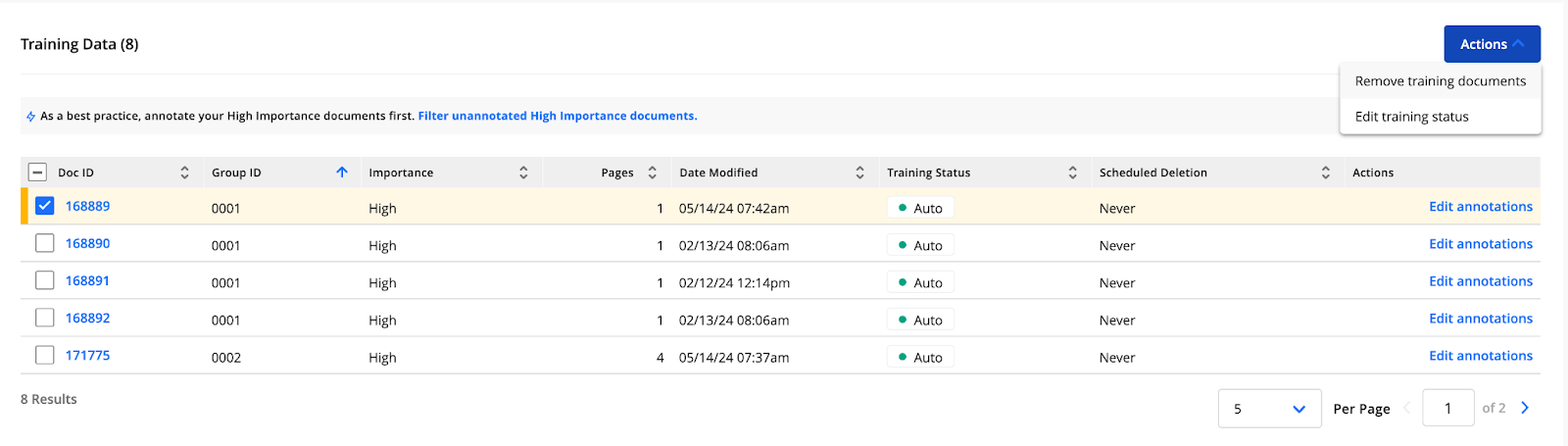
The Training Data table contains the following columns:
Doc ID — the ID number of your document
Group ID — the ID number of the document’s group. This ID is available after training analysis.
Importance — “High” or “Low,” depending on the results from the training data analysis
Pages — the number of pages in the specific document
Date Modified — the last time changes were made in the document
Training Status — the training status of your document:
Always — The document will always be used to train the model.
Auto — The document will be used to train the model until its scheduled deletion, based on the PII Data Deletion settings for your instance.
Never — The document will never be used in future model training, even if it hasn’t been deleted as part of the PII Data Deletion.
Loading — The document is currently being pre-processed and prepared for annotation.
Ready to annotate — The document has been uploaded successfully but has not been annotated yet.
Scheduled Deletion — the date the document is scheduled for deletion.
Actions — Each document has its own Actions link:
Annotate — available for documents that do not have any annotations.
Edit Annotations — available for documents that have already been annotated.
Learn how to annotate your documents to achieve a top-performing model in Step 5 in Training a Semi-structured Model.
Model History table
The Model History table, located at the bottom of the Model Management page, provides a comprehensive overview of your model's lifecycle. It displays the following columns:
Name — The name of the last available model for this layout.
Date Created — Date and time the model was created. Helps in tracking the model’s version history and ensures you’re working with the most recent model version.
Version — The specific version of the model that was trained on.
Source — Indicates where the model was trained—either within the current instance or externally and then uploaded to this instance.
Proj auto — Displays the predicted automation based on the Test Target Accuracy. Learn more in our Evaluating Model Training Results article.
Fields Layout / trained — Displays the number of fields in the current live layout vs. the number of fields the model was trained on. Numbers in parentheses show the difference between them.
Docs Trained — The total number of documents used for training the model.
Last Deploy — The last date and hour the model was deployed.
Actions — The options in this menu allow you to take the following actions on a model version:
Deploy
Undeploy
Download
In v40.2 and later, you can find specific records in the table in the following ways:
Filtering — Filter the contents of the Model History table by creation date, last-deploy date, source, and trainer version. Click Filter, and select the criteria that match what you’re looking for.
Searching — Search for a model version by name by entering a name in the search box.
Sorting — Sort the table's contents by clicking on the names of the following columns:
Name
Date created
Version
Source
Last deploy
Additionally, you can choose which columns are included in the table by clicking the menu next to the Filter drop-down list and clicking the Manage columns… option.
To train a Semi-structured model using TDM, see Training a Semi-structured Model.