Accessing the features mentioned in this article
Your access to some of the features mentioned in this article depends on your license package and pricing plan.
To learn which features are available to your organization and how to add more, contact your Hyperscience representative.
The Model Management page allows you to see a list of all models trained on this instance. In this article, you'll learn how to navigate the pages for different types of models.
To access the Model Management page, go to Library > Models.
Choose which type of models you want to see from the drop-down menu:
Identification Models - Field ID or Table ID models
Classification Models
Learn how to manage your Identification and Classification models in our Training Data Management article.
Text Classification Models
Transcription Models
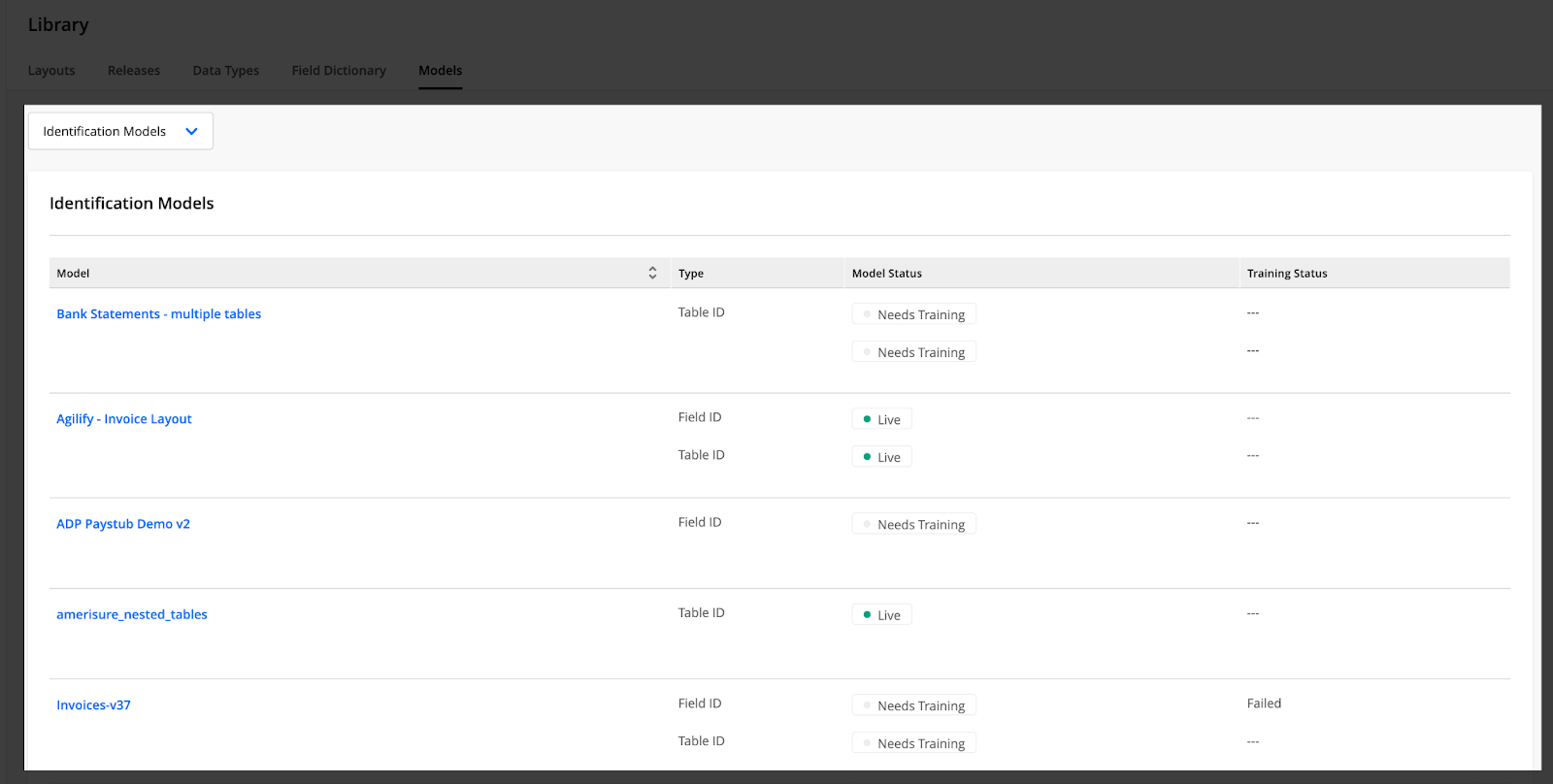
Identification Models table
Identification models are the default selected option in the drop-down menu at the top of the Models page. The Identification Models table displays a list of all the Semi-structured layouts available in your instance, along with their associated models.
The table has the following columns:
Model — shows the name of the model’s layout. This column is sortable.
Type — the type of locator models available for the layout: Field ID, Table ID, or both.
Model Status — the current status of the model. Possible statuses are:
Needs Training — The model needs to be trained and cannot be used in submission processing at this time.
Live — The model is trained and deployed.
Training Status — indicates the current state of the model training (e.g., Pending, In Progress, Failed, Canceled, or Last trained on [date]).
Learn more about Identification models in TDM for Identification Models.
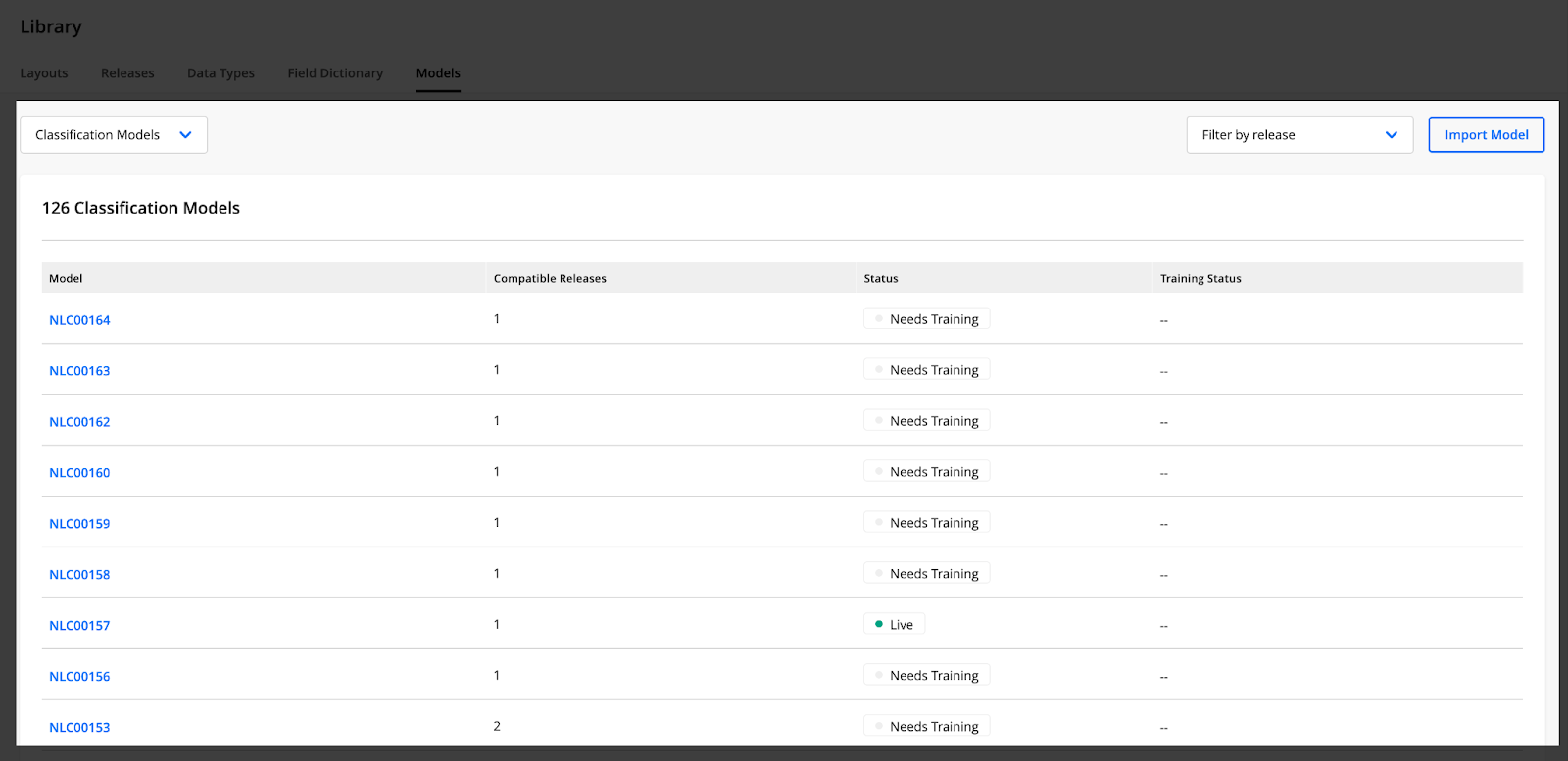
Classification Models Table
To access the Classification Models table, click on Classification Models in the drop-down menu at the top of the Models page.
A table with all Classification models appears:
You can filter the Classification Models table by release with the Filter by release drop-down list, which is located on the right-hand side of the page.
You can also access the model management page for a particular model by clicking on its name in the table.
You can import models by clicking the Import Model button in the upper-right corner of the page.
You can also see the number of Classification models available in your instance.
The Classification models table contains the following columns:
Model — shows the name of your Classification model
Compatible Releases — indicates the number of releases that the Classification model can generate predictions for
Status — displays the model's current state (e.g., Needs Training or Live)
Training Status — indicates the current state of the model training (e.g., Pending, In Progress, Failed, Canceled, or Last trained on [date]).
Learn more about Classification models in TDM for Classification.
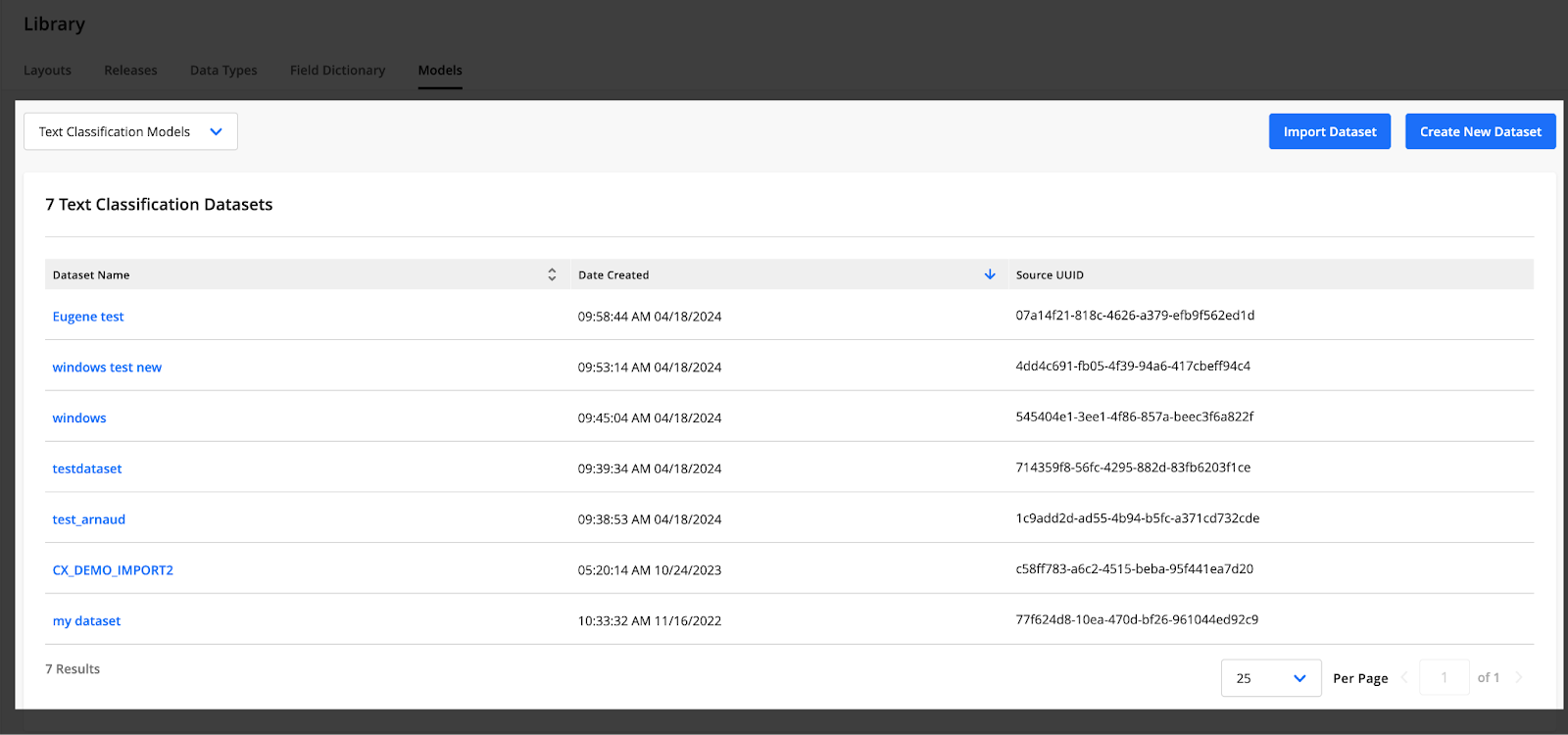
Text Classification Models Table
Access this table by selecting Text Classification Models from the drop-down menu at the top of the Models page.
You can import a dataset or create a new dataset by clicking on the buttons located above the table. The number of Text Classification datasets appears at the top.
The Text Classification Models table provides the following information for each model:
Dataset Name
Date Created
Source UUID
Learn more in Text Classification.
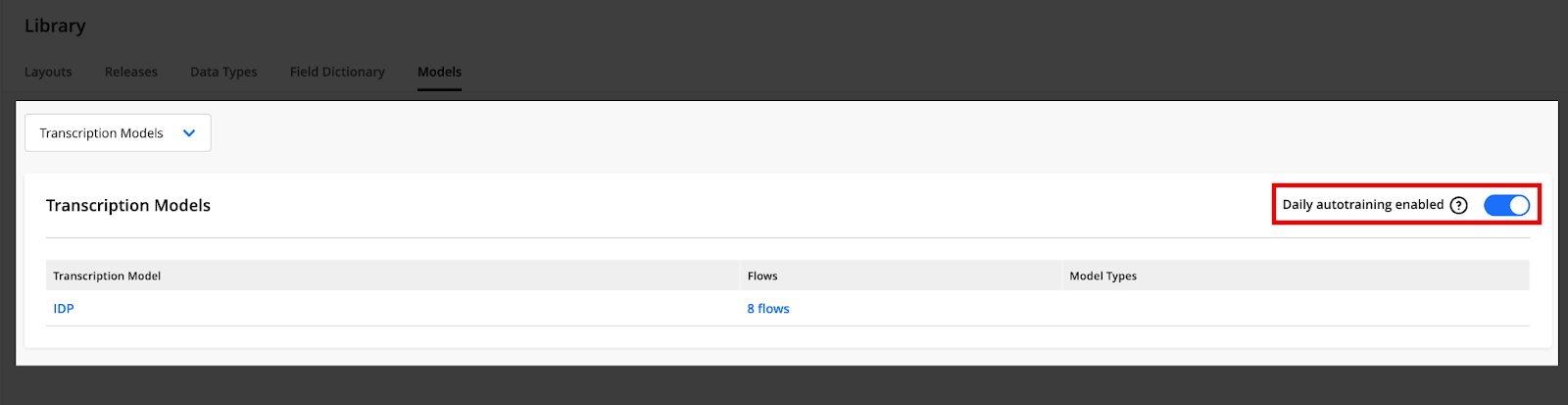
Transcription Models Table
Transcription models are collections of fine-tuning models. Select Transcription models from the drop-down menu at the top of the Models page to view all available fine-tuning models in your instance.
For each Transcription model, the table provides the following information:
Transcription Model — the name of the model
Flows — the number of flows using the model. Clicking this number reveals a list of the flows.
Each flow can have only one set of fine-tuning models assigned to it.
Model Types - The types of fine-tuning models that have at least one QA record available to them (e.g., Latin Semi-Structured, Checkbox, Signature).
Currently, it is not possible to create new sets of fine-tuning models in the application. If the transcription models listed in the Model Library do not meet your needs, contact your Hyperscience representative.
Daily Autotraining - Daily auto-training of fine-tuning models is enabled by default. It retrains all finetuning models daily based on the latest QA records. Note that the model training starts in the early morning (UTC time).
If you are not obtaining high-quality results from Transcription Supervision and QA tasks, consider disabling daily training to prevent it from affecting model performance. You can re-enable it after your results improve.
To enable or disable the daily training of your transcription models, click the Daily Autotraining enabled toggle.
Learn more about transcription models in Managing Transcription Models.